编译器开发-代码生成
代码生成阶段是AST转换为实际可运行代码的过程,在这里也就是说从AST到VM Code。在传统编译架构中一般是汇编,在现代编译架构中可以理解为IR,其核心就是我们要将高级语言的种种概念映射到CPU支持的指令上。
Jack Lang支持简单的OOP,而VM Code可没有这些概念,只有对内存的操作指令,Jack Lang的编译目标就是VM Code。
符号表
符号表是编译器中很重要的一个组件,用于记录高级语言中出现的变量。这是因为VM Code中对LCL,ARG等内存段的实际操作都是根据基址+偏移量进行读写的。符号表的作用就是记录变量名,数据类型,环境类型,出现的顺序,这里出现的顺序就是偏移量。

这就是一个符号表,index记录的是该kind类型的变量在该kind中出现的次序。通过符号表,我们就能根据某一变量名找到其偏移量,最终根据段基址(也就是该kind对应的内存段)+ 偏移量就能读写该变量。所以符号表实际上记录的就是变量在内存中的位置。
在Jack中有各种变量,这些属性是:
- name
- type(int, char, boolean, class name)
- kind(field, static, argument, local)
- scope(class level, subroutine level)
在单文件(单个Class)编译过程中只需要维护两个符号表:class level与subroutine level。
Class级别的变量(静态变量、实例变量)存储到class level中。function级别的变量(函数参数,函数局部变量)存储到subroutine level中。
依靠符号表,我们就能实现作用域了。在现代语言中,每一个block都会创建一个作用域,该作用域中创建的变量只在该作用域中可用,如果要读写一个不在该作用域中变量,那就需要根据作用域链一路向上查找。我们可以对每一个block都创建一个符号表,当读写某一变量时如果它不在当前作用域的符号表中,则在其父符号表中查找,直到查找到顶层符号表,它的模型是这样的:
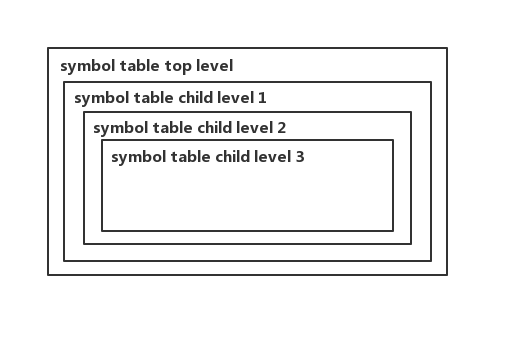
在实现时,可以使用HashTable存储符号表,然后使用链表将HashTable连接起来,查找变量时一个符号表一个符号表挨个查找,直到找到链表完结。
Class 代码生成
在Jack中每一个文件都是一个Class,Class的典型结构是这样的:
1class foo{
2 field int a;
3
4 static int b;
5
6 method void c(int x, int y){
7 // ...
8 }
9
10 static int d(int g, int b){
11 // ...
12 return g + b;
13 }
14}
在VM Code中并没有Class的概念,一切都是内存操作,具体来说就是对Stack与Heap的操作。在Jack Lang中变量使用分为两部分:变量声明与变量读写。对于变量声明,在class leve中就是顶部的field与static变量声明,在subroutine level中就是通过var声明,声明阶段并不实际创建变量,而是只将其添加到符号表中。所以对于整个Class的代码生成就包含两部分:添加Class level变量到符号表、生成function,最终产出的VM Code应该是这样:
function内的代码按照各个block是什么来决定生成何种代码。function指令的第二个参数nArgs表示函数包含nArgs个本地变量,代码生成时需要探测function内部var block中创建了多少个local变量。关于function指令可以参考函数声明与调用中的function部分。
局部变量定义
在前面说过任何变量在定义阶段都不生成实际代码,而是只添加变量信息到符号表中。在函数内局部变量也是如此。
静态函数调用
Jack Lang中静态函数就是使用static关键字标记的函数,使用do className.functionName(...args)调用。静态函数的代码生成与普通函数没什么区别,首先将args依次push到stack中,然后使用call functionName nArgs指令调用。这部分可以参考函数声明与调用中的call指令部分。
OOP的实现
OOP在Jack Lang中核心是这两部分:
- Class的实例化
- 调用实例方法
Class典型结构是这样的:
使用Class是这样:
class的实例(Object)的内容是存储在Heap中的,引用这个Object的变量在Stack中,变量的值存储Object的内存地址。他们在内存的位置是这样的:
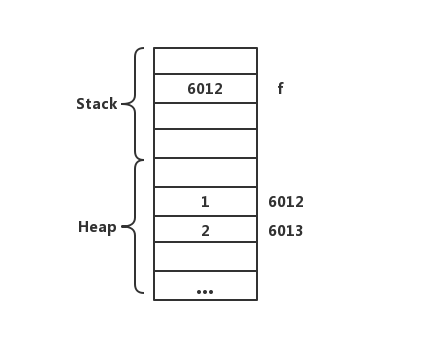
那么这个过程是怎么实现的呢?
首先var foo f;这一行同前面一样,不生成实际代码,再将变量类型添加到符号表中。之后使用call指令调用foo.new这一构造方法。在调用call指令前需要把参数push到Stack中,由于我们的new方法不需要参数,所以直接调用call指令即可。
在构造函数内首先需要使用Memory.alloc n来申请内存地址,该函数会返回一个申请指定大小内存块的基址,这里的n就是需要几个word,也就是class中实例变量的数量。然后需要将该基址写入到THIS内存段中,后续所有对class实例变量的操作都需要以内存段作为基址,加上符号表中的偏移量作为实际地址来访问。接着就需要按照构造函数内各种不同的block生成对应的VM Code。最后在Jack Lang中需要return this。这一步的作用是将构造函数中申请的Object地址返回出去,这一步就与函数声明与调用中return部分一样了,先把THIS地址push到Stack上,然后调用return指令即可。现在Class已经完成了实例化。
接着我们遇到了一个类实例方法调用,他与静态函数的唯一区别是,函数内部需要this的内存地址,因为这是一个实例方法,在实例方法中必须能够访问到当前类实例,也就是这个类的基址。通过该基址与符号表,在实例方法中访问该类的实例变量。那么该怎么让实例方法直到this是什么呢?很简单,在调用实例方法是,我们总是将该实例的基址当作第一个参数传递给实例方法并进行调用。
也就是说obj.foo(1, 2);这样的函数会被理解为foo(obj, 1, 2),我们依据后面的形式生成代码调用的VM Code即可。
在实例方法中,第一个参数就是this的内存地址,首先我们需要将THIS段内存的值设为第一个参数的值,也就是说在实例方法内,THIS段内存的值始终是该实例方法的第一个参数,也就是实例的内存地址。之后再根据一般的代码生成规则生成VM Code即可。
现在我们就已经实现了OOP中最核心的两部分:对象的实例化以及实例方法调用。可以看到OOP的实现只是面向过程的一些改进。
数组管理
数组是一块连续的内存区域,它也是存储在Heap中的。在Jack Lang中Array是一个内置类型。同Class一样,变量保存的是数组第一个元素的地址,就像下面一样:
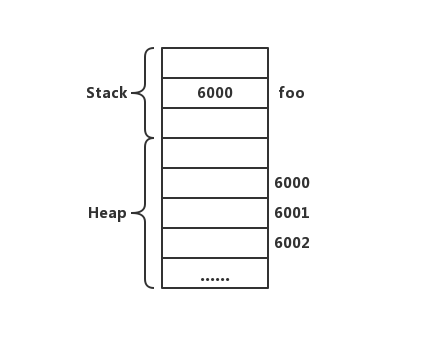
在VM Code中,我们使用THIS来管理Object的基址,使用THAT来管理Array的基址。所以对于数组的访问直接使用THAT加上偏移量即可。