编译器开发-词法分析
在编译器的前端首先进行的是词法分析(Lexical Analysis),也就是将一份源代码文本转换成抽象语法树(Abstract syntax tree,Aka AST)的过程,AST是一个token序列,token是语法中的原子单元,例如标识符、关键则、符号等。从数据结构角度看,AST是树形结构,例如下面这样:
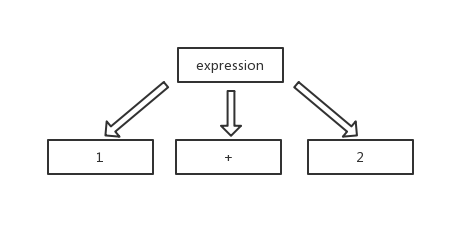
图中有一个表达式token,它由三个子token组成,分别是数字常量1、2,符号+。
要将源代码转换为AST,可以分为三个步骤:
- 预处理
- 生成token序列
- 根据token序列生成AST
预处理
预处理过程用来移除程序中的注释,如果不移除会为后面的过程增加额外的工作量。在各种语言中注释格式均有些区别,但总的来说可以归为两大类:
- 单行注释(从某几个特殊字符组合开始,其后的所有内容均为注释,例如 // 或者 # )
- 多行注释(使用特殊字符组合包裹某一片文本区域,其内的字符均为注释,例如 /**/ )
知道了规则就好办了,对于单行注释,遇到注释起始字符时,直接把起始字符到换行符前面的内容全删除。对于多行注释,则需从起始字符开始遍历文本,直到遇到了终止字符,然后将他们移除即可。
生成token序列
经过预处理的程序文本还是一整块的,在这一步我们要将所有原子单元拆开,但注意这一步不涉及生成AST,只是生成token序列,这个序列是线性的,不是树结构,例如下面的token序列:
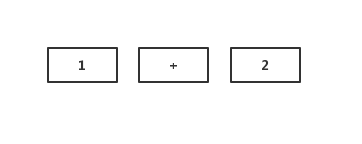
这个序列就包含三个token:1、+、2。
同时在生成token序列这一步,我们还要标记该token是一个什么类型的token,这一步是为后面生成AST做准备。
在绝大部分语言中,token或者说你写的代码中每一个独立的语法单元,都有一个类型,例如在下面的代码中:
就有这几种:
- function、return(keyword)
- add、a、b(identifier)
- (、)、{、}、,、+(symbol)
现代语言中所定义的token肯定会比上面的例子多,但原理上是一样的。
在生成token这一步,我们要根据空格,符号将程序文本拆开。为什么是空格与符号呢?因为语言的原子单元是通过空格与符号区分开的,例如function add,显然我知道这里有两个token,第一个是语言定义的keyword,第二个是用户定义的identifier。如果写成了functionadd,那它就只是一个单独的identifier。
切分token后,我们要标记token类型,这一步需要根据语言的定义情况来具体分析,但总的来说会有这三个步骤:
- 在函数定义的keyword中查找,找到了则将其标记为keyword,没找到则进入下一步
- 在函数定义的symbol中查找,找到了则将其标记为symbol,没找到则进入下一步
- 什么都没找到,那他就是一个identifier
现代语言中还会有别的分类或规则,在此就不做过多举例了,以目标语言的定义为主,但大体流程是这样。
经过tokenizer处理后,我们就将程序文本变成了token序列,接着就是我们的重头戏生成AST。
生成AST
生成AST的“过程”跟语言设计是强相关的。注意,这里是语言设计而不是你写的代码的语法结构,这是什么意思呢?
任何一种语言不论其支持的编程范式有哪些,其语法结构一定是固定的(运行时可能有不同含义,但从根本上来说不同含义还是根据固定的语法结构来确定的,例如Lisp)。以下面的变量定义为例:
1let a; // 只支持一次定义单个变量
1let a, b, c; // 支持一次定义多个变量
第一种语言定义只支持一次定义单个变量,那么在遇到int token时,生成AST的过程会是这样:
- 遇到了let,现在开始进行变量定义了,下一个token一定是一个identifier,如果出现了symbol或者keyword就报错
- 这个token是一个identifier,我把它存下来,下一个token一定是一个symbol,值为;,如果不是就报错
- 这个token是一个keyword,现在定义变量的block结束。
第二种语言定义支持一次定义多个变量,那么生成AST的过程就要多几步
- 遇到了let,现在开始进行变量定义了,下一个token一定是一个identifier,如果出现了symbol或者keyword就报错
- 这个token是一个identifier,我把它存下来,下一个token一定是一个symbol,值为;或者,,如果不是就报错
- 如果这个token是,,则跳转到到第二步,如果是;,则定义变量的block结束。
这就是语言设计对于生成AST的影响,语言设计的越复杂,生成AST所要考虑的情况也就越多。对于确定的语法规则,我们只要根据规则来匹配 “关键性的token”,就能生成正确的AST。注意,这里是关键性的token,意思是说只要遇到了某种token,就一定能确定后面的数个token的作用。例如上面的let,只要遇到了let,后面的几个token就一定是关于变量定义的。
分号机制
在一些语言中,语句的结束必须写分号,例如C,有些则不必,例如Python,JavaScript。两者并没有什么优略,只是语言设计上的选择。
也许你注意到了,上面的let语句,在遇到分号时,就表示let语句结束,那么如果支持一次定义多个变量,需要遍历token直到遇到分号。如果语言设计上可以不使用分号,则需要通过换行符来确定语句结束。
但实际上很有可能你写的代码是连续有多个换行符的,这就需要编译器在生成AST前的某一阶段将无用的换行符全部移除,同时需要确保不同token之间还是有正常symbol来进行分割的,这就造成了额外的工作量。使用分号则没有这个问题。
所以语言需不需要加分号,从语言设计角度是没有优劣之分的,但在实现上没有分号确实比有分号麻烦一点。
生成过程
现在开始真正的生成过程了,怎么生成呢?一个token一个token遍历?太麻烦了,而且容易出错。正确方式是将语言结构分割成不同的block,每一个block有一个或几个关键性的token,用于确定这是个什么block。每个block有不同的规则,我们一个个的去匹配block,再根据block的规则去匹配token,还是有点太抽象了,画个图来举例。

这里我们有5个block:
- function block
- let block
- if-else block
- return block
- expression block
他们的关键token分别是:
- function keyword
- let keyword
- if keyword
- return keyword
- [identifier|keyword](op [identifier|keyword])*
前4个很好理解,只要见到了对应的keyword,就表示这个block开始了。
最后的expression block相对麻烦些,它表示表达式block。单独出现a是一个表达式,a+b也是一个表达式,true也是一个表达式,在遇到identifier|keyword(非前面的block keyword)时,它是一个block,后面如果跟了一个symbol,然后又跟了一个identifier|keyword,他们也是一个表达式。当然这里做了简化处理,现代语言中表达式可能会很复杂。
function block规则为
function identifier(identifier[, identifier]) {[let block | if block | return block]}
let block规则为
let identifier = expression block;
if block规则为
if ( expression block ) {[let block | if block | return block]} else {[let block | if block | return block]}
return block规则为
return expression block;
expression block规则为
[identifier|keyword](op [identifier|keyword])*
这里采用了类似正则表达式的表示方法,以expression block为例,expression block期望一个identifier或者keyword,后面可以跟0-若干个symbol + identifier或者keyword。
有了这一套规则,就可以生成AST了,我们将不同的block写成不同的函数,当遇见关键token时,就调用对应的block函数,以,各个block的函数彼此嵌套调用,最终就能组合成一个AST。
以上只是一个简化版的示例,现代语言可比这复杂的多了。在实际过程中,还会遇上语法推导的问题,例如a[1]与a(1),前者是一个列表访问,后者是一个函数调用,当token处理到a时,后面的状态是无从知晓的,此时需要向后读1个token来决定选择哪个语法,称为LL分析法。